Airflow 101: working locally and familiarise with the tool¶
Pre-requisites¶
The following prerequisites are needed:
- Libraries detailed in the Setting up section (either via conda or pipenv)
- MySQL installed
- text editor
- command line
Getting your environment up and running¶
If you followed the instructions you should have Airflow installed as well as the rest of the packages we will be using.
So let’s get our environment up and running:
If you are using conda start your environment via:
$ source activate airflow-env
If using pipenv then:
$ pipenv shell
this will start a shell within a virtual environment, to exit the shell you need to type exit and this will exit the virtual environment.
Starting Airflow locally¶
Airflow home lives in ~/airflow by default, but you can change the location before installing airflow. You first need to set the AIRFLOW_HOME environment variable and then install airflow. For example, using pip:
export AIRFLOW_HOME=~/mydir/airflow
# install from PyPI using pip
pip install apache-airflow
once you have completed the installation you should see something like this in the airflow directory (wherever it lives for you)
drwxr-xr-x - myuser 18 Apr 14:02 .
.rw-r--r-- 26k myuser 18 Apr 14:02 ├── airflow.cfg
drwxr-xr-x - myuser 18 Apr 14:02 ├── logs
drwxr-xr-x - myuser 18 Apr 14:02 │ └── scheduler
drwxr-xr-x - myuser 18 Apr 14:02 │ ├── 2019-04-18
lrwxr-xr-x 46 myuser 18 Apr 14:02 │ └── latest -> /Users/myuser/airflow/logs/scheduler/2019-04-18
.rw-r--r-- 2.5k myuser 18 Apr 14:02 └── unittests.cfg
We need to create a local dag folder:
mkdir ~/airflow/dags
As your project evolves, your directory will look something like this:
airflow # the root directory.
├── dags # root folder for all dags. files inside folders are not searched for dags.
│ ├── my_dag.py, # my dag (definitions of tasks/operators) including precedence.
│ └── ...
├── logs # logs for the various tasks that are run
│ └── my_dag # DAG specific logs
│ │ ├── src1_s3 # folder for task-specific logs (log files are created by date of a run)
│ │ ├── src2_hdfs
│ │ ├── src3_s3
│ │ └── spark_task_etl
├── airflow.db # SQLite database used by Airflow internally to track the status of each DAG.
├── airflow.cfg # global configuration for Airflow (this can be overridden by config inside the file.)
└── ...
Spinning up a local airflow instance¶
➡️ The first thing we need to do is initialize Airflow database:
airflow initdb
This will be cfrated in airflow.db by default.
airflow_home
├── airflow.cfg
├── airflow.db <- Airflow SQLite DB
└── unittests.cfg
💡Using SQLite is an adequate solution for local testing and development, but it does not support concurrent access. In a production environment you will most certainly want to use a more robust database solution such as Postgres or MySQL (see optional section at the bottom on how to do this locally).
Now we need to launch a terminal an start the Airflow web server (which is a Flask application):
airflow webserver -p 8080
Now we can head over to http://localhost:8080 now and you will see that there are a number of examples DAGS already there.
Troubleshooting¶
If you have any issues with loading the Airflow console in your web browser, or if there were any errors when you ran airflow webserver, then you may have another application running on port 8080. That’s the default port for Airflow, but you can change it to any other user port that’s not being used. For example, to run Airflow on port 7070 you could run:
airflow webserver -p 7070
🚦 Take some time to familiarise with the UI and get your local instance set up

These are the buttons that allow you to enable, trigger and refresh dags.
Airflow connections¶
Now let’s have a look at the connections (http://localhost:8080/admin/connection/) go to admin > connections. You should be able to see a number of connections available.
These allows you to add services or integrate tools with your airflow server.
Commands¶
Let us go over some of the commands. Back on your command line:
airflow list_dags
we can list the DAG tasks in a tree view
airflow list_tasks tutorial --tree
we can tests the dags too, but we will need to set a date parameter so that this executes:
airflow test tutorial print_date 2019-09-02
(note that you cannot use a future date or you will get an error)
airflow test tutorial templated 2019-09-02
By using the test commands these are not saved in the database.
You can also use the command line to enable and trigger DAGS, similar to the buttons in the GUI above:
# enable/disable
airflow unpause <your DAG>
airflow pause <your DAG>
# trigger
airflow trigger_dag <your DAG>
Now let’s start the scheduler:
airflow scheduler
Behind the scenes, it monitors and stays in sync with a folder for all DAG objects it contains. The Airflow scheduler is designed to run as a service in an Airflow production environment.
Now with the schedule up and running we can trigger an instance:
$ airflow run airflow run example_bash_operator runme_0 2015-01-01
This will be stored in the database and you can see the change of the status change straight away.
What would happen for example if we wanted to run or trigger the tutorial task? 🤔
Let’s try from the CLI and see what happens.
airflow trigger_dag tutorial
Writing your first DAG¶
Let’s create our first simple DAG.
Inside the dag directory (~/airflow/dags) create a simple_dag.py file.
- Import Python dependencies
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
- Default Airflow arguments
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": datetime(2019, 4, 30),
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
# If a task fails, retry it once after waiting
# at least 2 minutes
"retries": 1,
"retry_delay": timedelta(minutes=2),
}
- Instantiate the DAG:Give the DAG name, configure the schedule, and set the DAG settings
dag = DAG(
"hello_world",
description="Simple tutorial DAG",
schedule_interval="0 12 * * *",
default_args=default_args,
catchup=False,
)
Here are a couple of options you can use for your schedule_interval. You can choose to use some preset argument or cron-like argument:
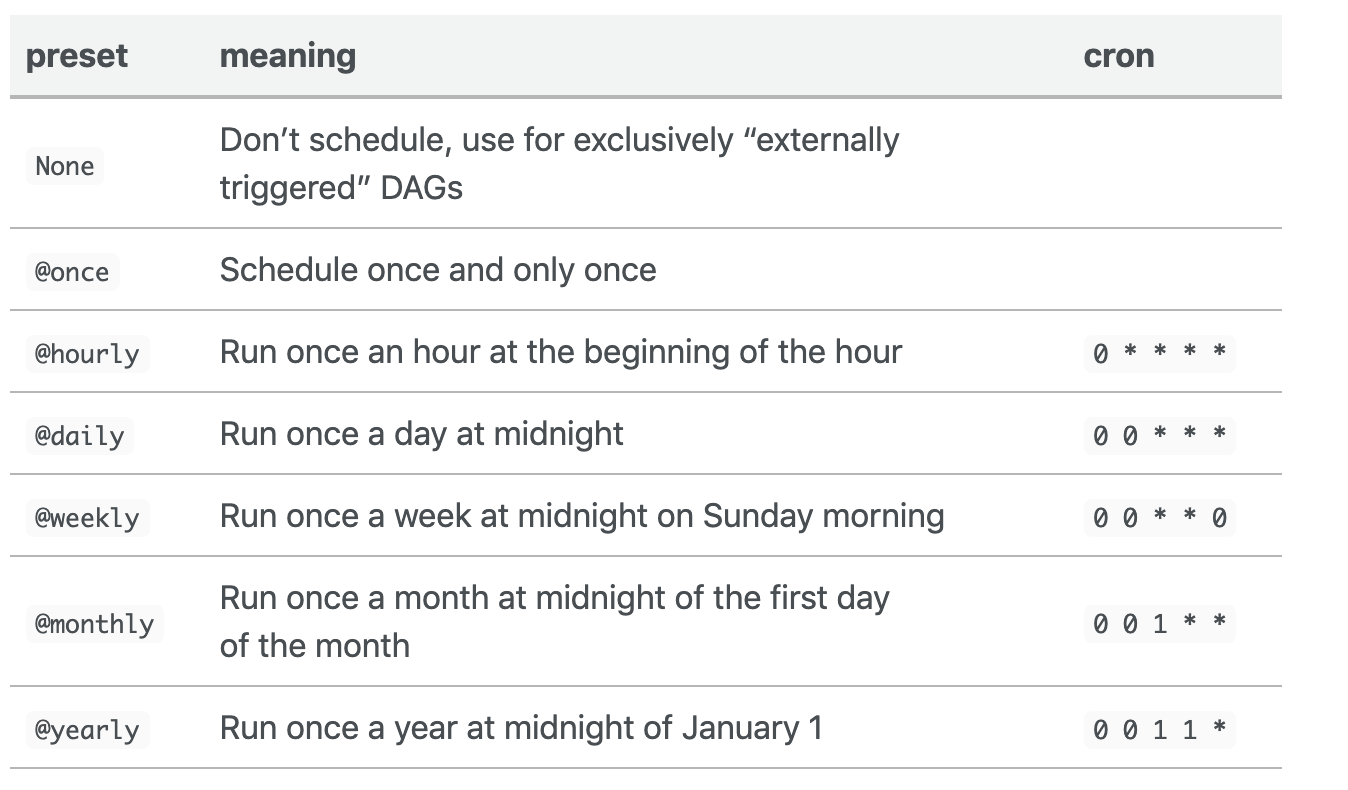
For example
schedule_interval='@daily'
schedule_interval='0 0 * * *'
For reference https://devhints.io/cron or https://www.codementor.io/akul08/the-ultimate-crontab-cheatsheet-5op0f7o4r
- Layout your tasks
t1 = DummyOperator(task_id="dummy_task", retries=3, dag=dag)
t2 = PythonOperator(task_id="hello_task", python_callable=print_hello, dag=dag)
- Setting dependencies Set the order of the tasks
t1 >> t2
Other ways
# This means that t2 will depend on t1
# running successfully to run.
t1.set_downstream(t2)
# similar to above where t3 will depend on t1
t3.set_upstream(t1)
# And the upstream dependency with the
# bit shift operator:
t2 << t1
# A list of tasks can also be set as
# dependencies. These operations
# all have the same effect:
t1.set_downstream([t2, t3])
t1 >> [t2, t3]
[t2, t3] << t1
Your final DAG should look like this
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
def print_hello():
return "Hello world!"
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": datetime(2019, 8, 31),
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
# If a task fails, retry it once after waiting
# at least 2 minutes
"retries": 1,
"retry_delay": timedelta(minutes=2),
}
dag = DAG(
"hello_world",
description="Simple tutorial DAG",
schedule_interval="0 12 * * *",
default_args=default_args,
catchup=False,
)
t1 = DummyOperator(task_id="dummy_task", retries=3, dag=dag)
t2 = PythonOperator(task_id="hello_task", python_callable=print_hello, dag=dag)
# sets downstream foe t1
t1 >> t2
# equivalent
# t2.set_upstream(t1)
If it is properly setup you should be able to see this straight away on your instance.
You should be able to trigger this DAG straight away.
Your first operator¶
An Operator is an atomic block of workflow logic, which performs a single action. Operators are written as Python classes (subclasses of BaseOperator), where the __init__ function can be used to configure settings for the task and a method named execute is called when the task instance is executed.
The execute method may also raise the AirflowSkipException from airflow.exceptions. In such a case the task instance would transition to the Skipped status.
If another exception is raised, the task will be retried until the maximum number of retries is reached.
🚦We need to create a new directory:
mkdir <airflow home>/plugins
Then my_operators.py
import logging
from airflow.models import BaseOperator
from airflow.plugins_manager import AirflowPlugin
from airflow.utils.decorators import apply_defaults
log = logging.getLogger(__name__)
class MyFirstOperator(BaseOperator):
@apply_defaults
def __init__(self, my_operator_param, *args, **kwargs):
self.operator_param = my_operator_param
super(MyFirstOperator, self).__init__(*args, **kwargs)
def execute(self, context):
log.info("Hello World!")
log.info('operator_param: %s', self.operator_param)
class MyFirstPlugin(AirflowPlugin):
name = "my_first_plugin"
operators = [MyFirstOperator]
In this file we are defining a new operator named MyFirstOperator. Its execute method is very simple, all it does is log “Hello World!” and the value of its own single parameter. The parameter is set in the __init__ function.
Now, we’ll need to create a new DAG to test our operator. Create a dags/test_operators.py file and fill it with the following content:
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from my_operators import MyFirstOperator
dag = DAG('my_test_dag', description='Another tutorial DAG',
schedule_interval='0 12 * * *',
start_date=datetime(2019, 8, 31), catchup=False)
dummy_task = DummyOperator(task_id='dummy_task', dag=dag)
operator_task = MyFirstOperator(my_operator_param='This is a test.',
task_id='my_first_operator_task', dag=dag)
dummy_task >> operator_task
🧪 OPTIONAL: Changing your database for a MySQL database¶
As we mentioned before Airflow uses a database to keep track of the tasks and their statuses. So it is critical to have one set up.
To start the default database we can run
airflow initdb. This will initialize your database via alembic so that it matches the latest Airflow release.
The default database used is sqlite which means you cannot parallelize tasks using this database. Since we have MySQL and MySQL client installed we will set them up so that we can use them with airflow.
🚦Create an airflow database
From the command line:
MySQL -u root -p
mysql> CREATE DATABASE airflow CHARACTER SET utf8 COLLATE utf8_unicode_ci;
mysql> GRANT ALL PRIVILEGES ON airflow.* To 'airflow'@'localhost';
mysql> FLUSH PRIVILEGES;
and initialize the database:
airflow initdb
Notice that this will fail with the default airflow.cfg
Update your local configuration¶
Open your airflow configuration file ~/airflow/airflow.cf and make the following changes:
executor = CeleryExecutor
# http://docs.celeryproject.org/en/latest/userguide/configuration.html#broker-settings
# needs rabbitmq running
broker_url = amqp://guest:guest@127.0.0.1/
# http://docs.celeryproject.org/en/latest/userguide/configuration.html#task-result-backend-settings
result_backend = db+mysql://airflow:airflow@localhost:3306/airflow
sql_alchemy_conn = mysql://airflow:python2019@localhost:3306/airflow
Here we are replacing the default executor (SequentialExecutor) with the CeleryExecutor so that we can run multiple DAGs in parallel.
We also replace the default sqlite database with our newly created airflow database.
Now we can initialize the database:
airflow initdb
